
AI-For-Beginners: 人人都能学人工智能!(一)
人工智能简介
人工智能是一门研究如何让计算机表现出智能行为,例如做人类擅长做的事情。
最初,计算机是由查尔斯·巴贝奇发明的,现代计算机虽然比19世纪提出的原始模型先进得多,但仍然遵循受控计算的理念。因此,如果我们知道实现目标所需的确切步骤顺序,就有可能对计算机进行编程,使其执行某些操作。

Photo of a person
Photo by Vickie Soshnikova
✅ 从一个人的相片中确定其年龄是一项无法明确编程的任务,因为我们不知道在做这件事时我们的脑海中是如何得出一个数字的。
然而,有些任务我们并不明确知道如何解决。如根据一个人的照片来确定其年龄, 我们无法对计算机进行编程来做到这一点。这正是需要人工智能(简称AI)解决的任务。
✅ 想想哪些任务可以交给计算机处理,从而受益于人工智能。想想金融、医学和艺术领域——这些领域如今是如何从人工智能中获益的?
弱人工智能与强人工智能
智力的定义和图灵测试

Photo of a Cat
Photo by Amber Kipp from Unsplash
要了解“智力”一词的模糊性,请尝试回答一个问题:“猫聪明吗?”。不同的人往往会对这个问题给出不同的答案,因为目前还没有一个普遍接受的测试来证明这个说法是否正确。如果你觉得有的话,那就试试给你的猫做个智商测试吧……
✅ 想一想,你该如何定义“智力”。一只能走出迷宫、找到食物的乌鸦算智力吗?一个孩子算智力吗?
人工智能的不同实现
如果我们希望计算机能够像人类一样运作,我们就需要以某种方式在计算机内部模拟我们的思维方式。因此,我们需要尝试理解是什么让人类变得智能。
为了能够将智能编程到机器中,我们需要了解我们自己的决策过程是如何进行的。如果你稍微反省一下,你就会意识到有些过程是在潜意识中发生的——例如,我们不用思考就能区分猫和狗——而有些过程则需要推理。
解决这个问题有两种可能的方法:
自上而下的方法
在自上而下的方法中,我们尝试对推理进行建模。由于我们在推理时能够遵循自己的思路,因此我们可以尝试将这个过程形式化,并在计算机内部进行编程。这被称为符号推理。
人们的头脑中往往会有一些规则来指导他们的决策过程。例如,当医生诊断病人时,他或她可能会意识到病人发烧,因此身体内部可能发生了一些炎症。通过将大量规则应用于特定问题,医生也许能够得出最终的诊断。
这种方法很大程度上依赖于知识表示和推理。从人类专家那里提取知识可能是最困难的部分,因为在很多情况下,医生并不知道他或她为什么会得出特定的诊断。有时,解决方案会在他/她的脑海中自动出现,无需经过明确的思考。有些任务,例如根据照片确定一个人的年龄,根本不能归结为操纵知识。
自下而上的方法
或者,我们可以尝试模拟我们大脑中最简单的元素——神经元。我们可以在计算机内部构建所谓的人工神经网络,然后通过提供示例来尝试教它解决问题。该过程类似于新生儿通过观察了解周围环境的过程。
人工智能简史
人工智能(AI)始于二十世纪中叶。最初,符号推理是一种流行的方法,并取得了许多重要的成就,例如专家系统——能够在某些特定问题领域充当专家的计算机程序。然而,人们很快发现,这种方法的可扩展性不佳。从专家那里提取知识,将其表示在计算机中,并保持知识库的准确性是一项非常复杂的任务,而且在许多情况下成本过高,不切实际。这导致了20世纪70年代所谓的“人工智能寒冬”。
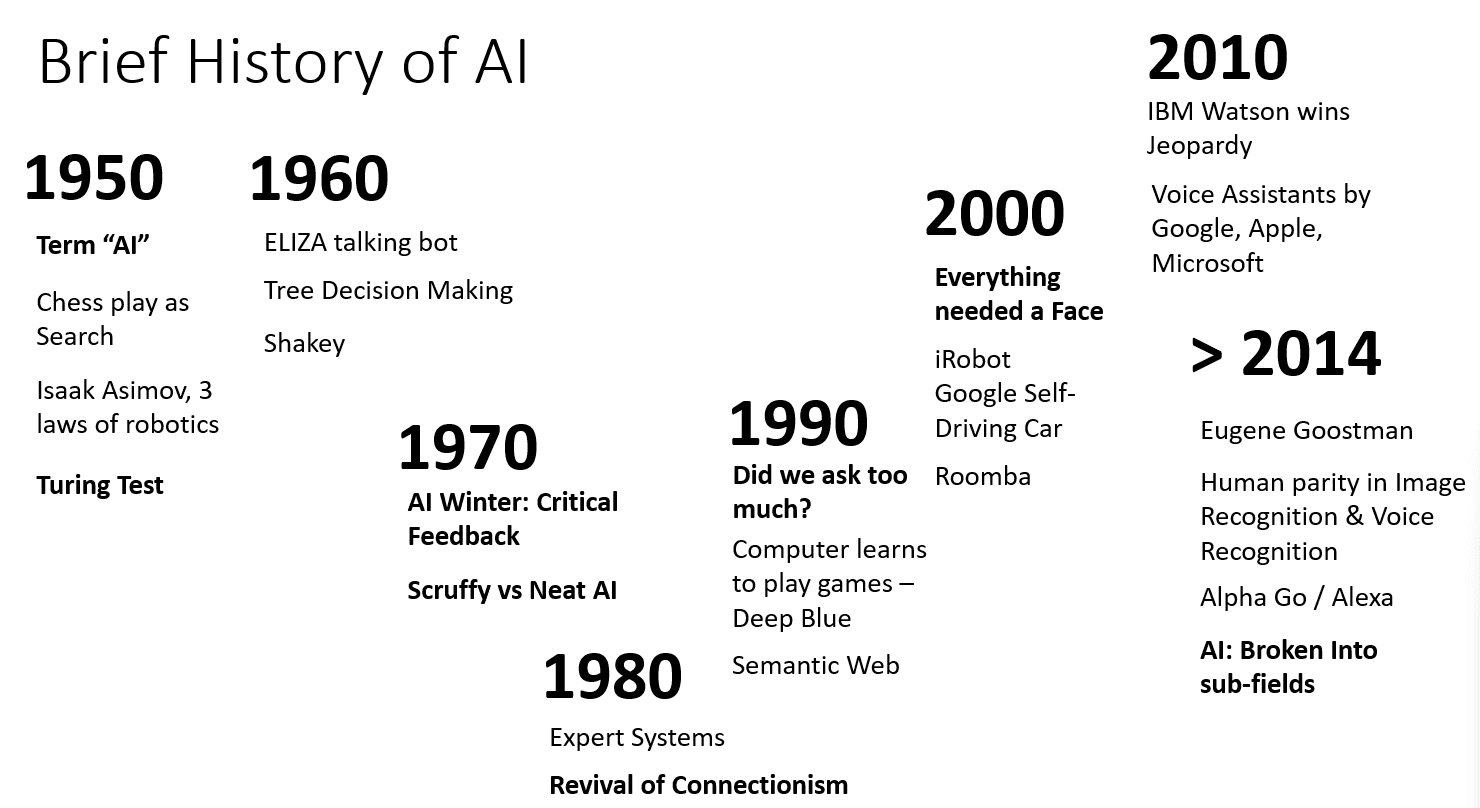
Image by Dmitry Soshnikov
随着时间的推移,计算资源变得越来越便宜,可用的数据也越来越多,因此神经网络方法开始在计算机视觉或语音理解等许多领域展现出与人类竞争的卓越性能。在过去的十年中,“人工智能”一词主要用作神经网络的同义词,因为我们听到的大多数人工智能成功案例都基于神经网络。
我们可以观察到方法是如何变化的,例如,在创建一个下棋的计算机程序时:
• 早期的国际象棋程序基于搜索——程序会明确地尝试估计对手在给定步数下可能采取的走法,并根据在几步之内能够取得的最优位置来选择最佳走法。这导致了所谓的 alpha-beta 剪枝搜索算法的发展。
• 搜索策略在游戏接近尾声时效果良好,因为此时搜索空间受限于少数可能的走法。然而,在游戏初期,搜索空间巨大,可以通过学习人类玩家之间的现有匹配来改进算法。后续实验采用了所谓的基于案例的推理,程序会在知识库中寻找与游戏当前位置非常相似的案例。
• 现代程序之所以能够战胜人类,是因为它们基于神经网络和强化学习。这些程序的学习方式完全是通过长时间的自我对弈并从错误中学习——就像人类学习下棋一样。然而,计算机程序可以在更短的时间内下更多盘棋,因此学习速度更快。
类似地,我们可以看到创建“会说话的程序”(可能通过图灵测试)的方法是如何改变的:
• 早期的此类程序(例如 Eliza)基于非常简单的语法规则以及将输入句子重新表述为问题。
• 现代助手,例如 Cortana、Siri 或 Google Assistant 都是混合系统,它们使用神经网络将语音转换为文本并识别我们的意图,然后采用一些推理或明确的算法来执行所需的操作。
• 未来,我们或许可以期待一个完全基于神经网络的模型能够独立处理对话。近期的 GPT 和 Turing-NLG 神经网络系列在这方面展现了巨大的成功。
近期人工智能研究
神经网络研究的近期巨大增长始于 2010 年左右,当时大型公共数据集开始可用。
一个名为 ImageNet 的庞大图像集包含约 1400 万张带注释的图像,由此催生了 ImageNet Large Scale Visual Recognition Challenge.。

ILSVRC Accuracy
Image by Dmitry Soshnikov
2012年,卷积神经网络首次应用于图像分类,分类错误率显著下降(从近30%降至16.4%)。2015年,微软研究院的ResNet架构达到了人类水平的准确率。
从那时起,神经网络在许多任务中表现出非常成功的行为:
在过去的几年中,我们见证了大型语言模型(例如 BERT 和 GPT-3)的巨大成功。发生这种情况主要是因为有大量可用的通用文本数据,使我们能够训练模型来捕捉文本的结构和含义,在通用文本集合上对其进行预训练,然后将这些模型专门用于更具体的任务。我们将在本课程的后面学习更多有关自然语言处理的知识。